RL기반 LLM Alignment tuning 방법론 중 하나인 DPO Loss 유도과정을 이해
DPO는 별도 보상모델 없이 정책모델의 확률분포 자체로 인간의 선호를 직접 학습
RLHF(Christiano, Paul et al., 《Deep Reinforcement Learning from Human Preferences》, 2017.) 에서 단점을 극복하기 위해 DPO(Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, Chelsea Finn, Direct Preference Optimization: Your Language Model is Secretly a Reward Model, 2023, arXiv) 라는 방법론이 나왔다.
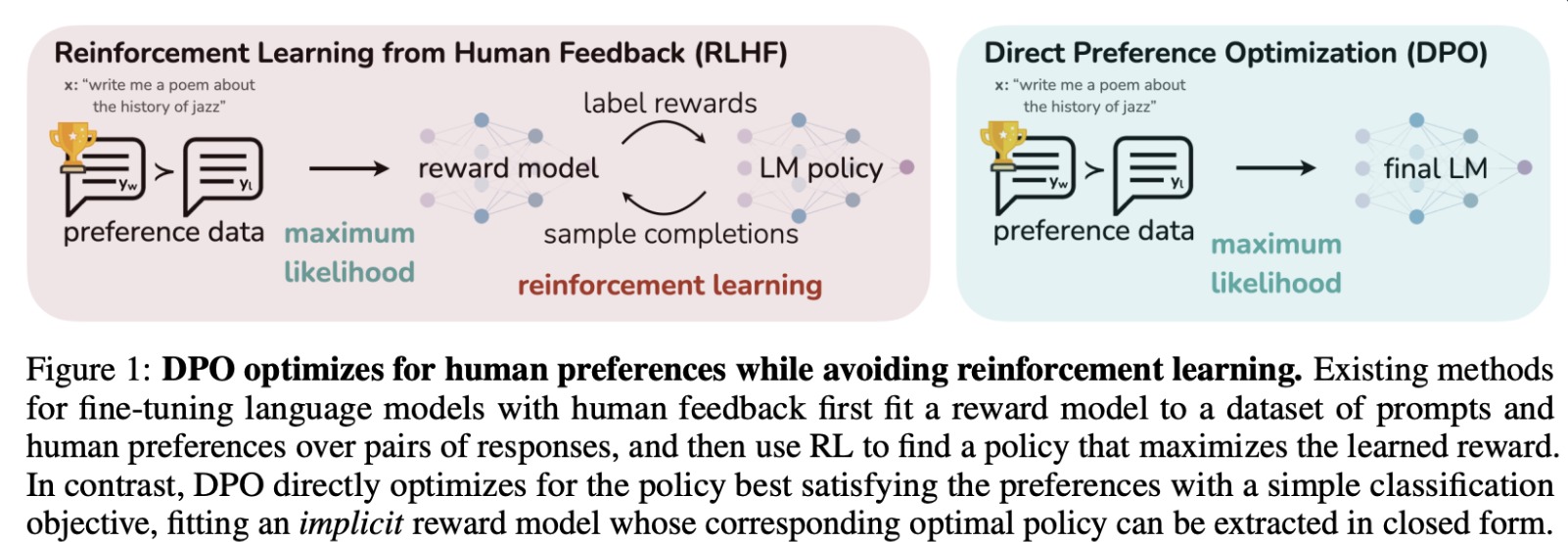
아래 그림과같이 DPO에서는 RLHF의 Reward model + RL 단계를 RL 한 단계로 줄이는 방법이다.
DPO의 Loss 유도과정을 ChatGPT에 물어보니 설명을 잘 해주어, 기록해 보았다. ChatGPT 4.5 대화 기록
RLHF에서 DPO Loss 유도 과정 대화 기록
사용자 요청
강화학습 관련하여 RLHF의 Loss에서 DPO의 Loss를 유도하는 과정에 대해서 설명 요청.
RLHF의 기본 개념
- RLHF: 인간 피드백을 통한 강화학습. 두 가지 주요 단계로 구성.
- 보상 모델 학습
- 정책 모델 최적화
보상 모델 Loss
정책 모델 목적함수
DPO Loss 유도 과정
최적 정책 π*(y|x)를 라그랑지 승수법으로 유도하면:
- 목적함수:
- 라그랑지언을 사용해 제약조건
(∑_y π_θ(y|x)=1)처리:
- 최적 조건 미분하여 정리하면 최적 정책 형태 얻음:
DPO의 Loss 함수 최종 형태
DPO 논문에서는 보상모델을 제거하고 정책모델 자체를 직접 최적화하는 형태로 Loss를 제시:
DPO Loss 직관적 이해
- DPO는 별도 보상모델 없이 정책모델의 확률분포 자체로 인간의 선호를 직접 학습.
- 선호 응답은 높은 확률, 비선호 응답은 낮은 확률로 유도함.
DPO 방식의 장점
- RLHF의 복잡성을 줄이고 간단한 최적화 문제로 만듦.
- 학습이 안정적이고 효율적이며 성능도 우수함.
위의 내용을 통해 RLHF에서 DPO Loss가 유도되는 전 과정을 설명 완료.
Last updated on March 17, 2025, 7:02 p.m.
LEAVE A COMMENT
부연 설명: 라그랑지언 loss를 최적 정책으로 미분하면 0이 되는데 이것을 정리하면 최적 정책이 ref 정책에 대해 보상값이 높은 응답의 확률이 증가비율을 곱한 형태가 됨.