[SIGIR'24] Setwise Approach for Effective and Highly Efficient Zero-shot Ranking with Large Language Models
setwise prompting 기법으로 Zero-shot document ranking 즉, LLM-based zero-shot ranking task에서 높은 효율성과 우위 달성한 방법. Re-ranking에 초점이 맞춰짐
[SIGIR'24] Setwise Approach for Effective and Highly Efficient Zero-shot Ranking with Large Language Models
호주 CSIRO 연구 그룹에서 Google Research의 Honglei Zhuang와 합작하여 게제한 논문
Motivation & Contribution
setwise prompting 기법으로 Zero-shot document ranking 즉, LLM-based zero-shot ranking task에서 높은 효율성과 우위 달성한 방법. Re-ranking에 초점이 맞춰짐.
- LLM-based zero-shot ranking은 pointwsie, pairwise, listwise 등 다양하게 연구가 되었는데 본 논문에서 속도, 성능면에서 우수한 setwise 기법이 제안됨.
- 기존 방법들 대비 속도, 성능 면에서 우수함을 입증하는 다양한 evaluation 로직들이 소개 됨
Related Works
논문 전개가 기존 방법들과의 결과를 비교하며 진행됨. candidate 문서들로 re-ranking 하는 task에 대한 prompt 기법들임.
- (a) pointwise: generation(yes or no)를 이용하냐 likelihood(QLM)을 이용하냐 차이로 2가지로 나뉘는 데 둘다 중간 logit이 필요해서 closed-source LLM에 사용 불가. 게다가 후보 문서 각각 LLM inference가 필요해서 비효율.
- (b) listwise: 한번에 모든 후보 문서들을 넣고 re-ranked된 결과를 뽑는 방법. 이떄 input length에 제약이 있기 때문에 후보 문서들 리스트를 sliding window 형태로 넣어주는 것들 반복하여 극복함. 하지만, 성능이 떨어지는듯함.
- (c) pairwise: 후보 문서를 pairwise로 짝지어 query와 관련성에 대한 비교 우위를 계산해 re-ranking 함. 하지만 모든 pair에 대해 비교우위를 계산해놓는 비효율을 완화하기 위해 sampling, sorting(heap sort, buble sort)알고리즘 등이 사용됨.
- (d) setwise: pairwise에서 sorting 알고리즘에 집중해 이를 개선시키고자 함(뒤에서 자세히 설명). 한번의 LLM inference에서 set-size 만큼의 후보 문서들에 대한 relevant score가 포함된 ordered list를 출력해 사용.
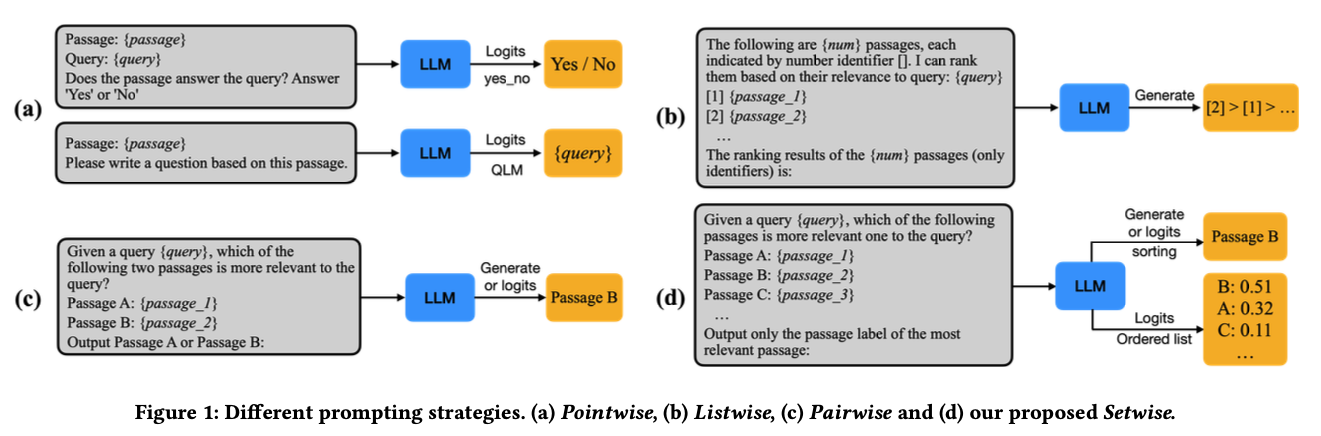
Setwise Ranking Prompting
pairwise 측면에서 setwise가 다른점은 pair단위로 비교하는게 아니라 예를들어 하나더 봐서 다음과 같이 서개씩 비교하면 성능이 개선된다는 점이다. heap sort 와 bubble sort 측면서 설명하는 그림임.
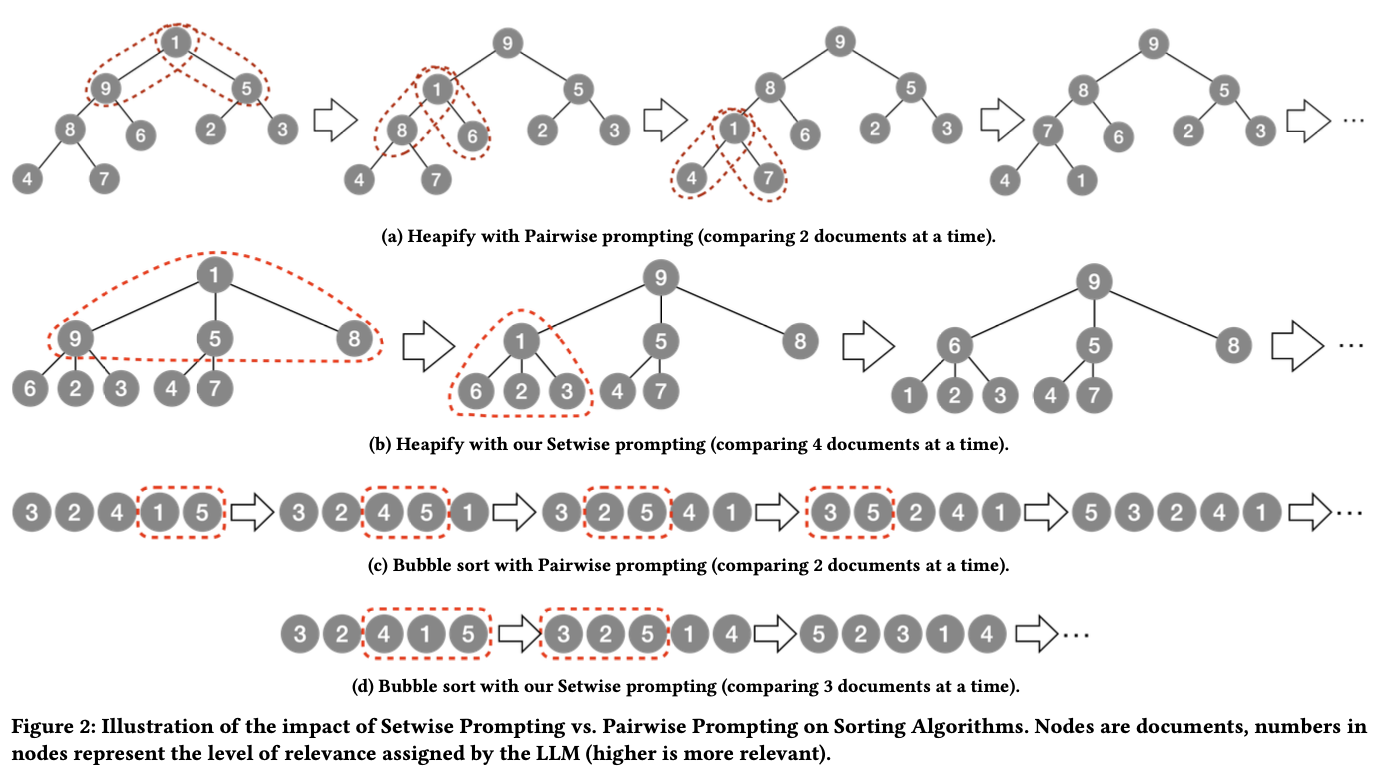
listwise 측면에서 모든 후보군에 대한 re-ranked 된 결과를 sliding window 방식으로 각각 뽑아 aggregation하는 과정에서 sliding window 간에 중복되는 문서셋이 존재 하기 때문에 비효울적임. setwise 방식은 subset 후보간의 비교가 독립적으로 취급되기 때문에 중복 비교를 피할 수 있고 이로인해 LLM inference 수, 그리고 생성되는 token 수도 줄어듦.
따라서, 이론적으로 다음과 같이 setwise 방법의 gain을 도식화 할 수 있음.

개인 견해: 사실 제안된 방법의 아이디어가 simple하고, 이론적으로는 스케일이 크게 개선되는 느낌이 아니긴 함.
Experiments
Implementation details에 제공된 정보로는 Lisewise 방법에서 window-size는 4, step-size는 2 가 사용되었다고 함. Setwise의 비교문서 수는 3개, BM25 는 pyserini 를 사용.
TREC DL datasets에 대해 실험 결과를 뽑아 보니 BM25 보단 월등히 좋고, 성능 면에서는 pairwise 랑 비등한 결과를 보임. 단, 속도는 많이 빨라짐. 여기있는 성능 표의 비교 문서수 는 3으로 고정 됨.
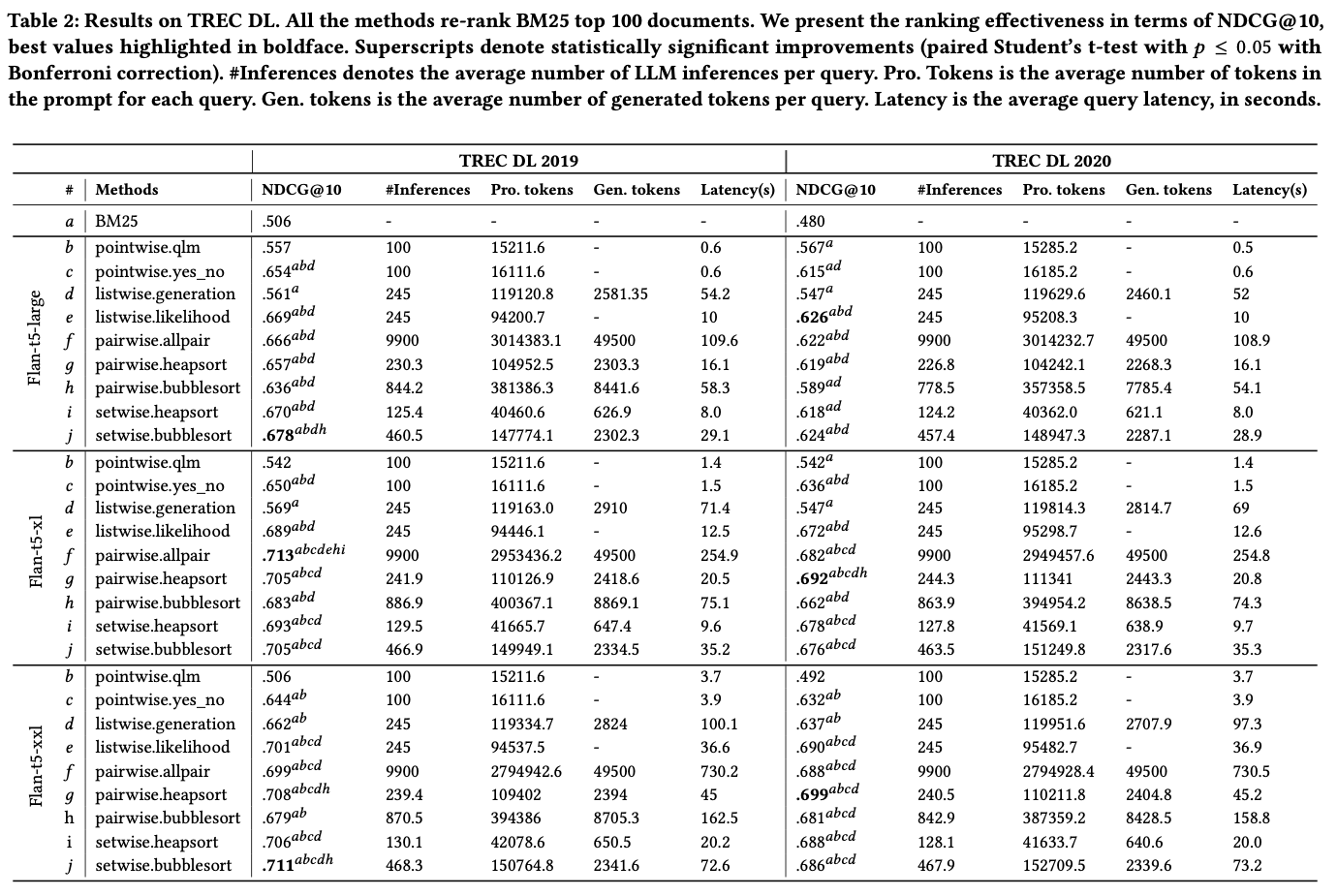
LLM 파라미터 수, 그리고 비교 문서수
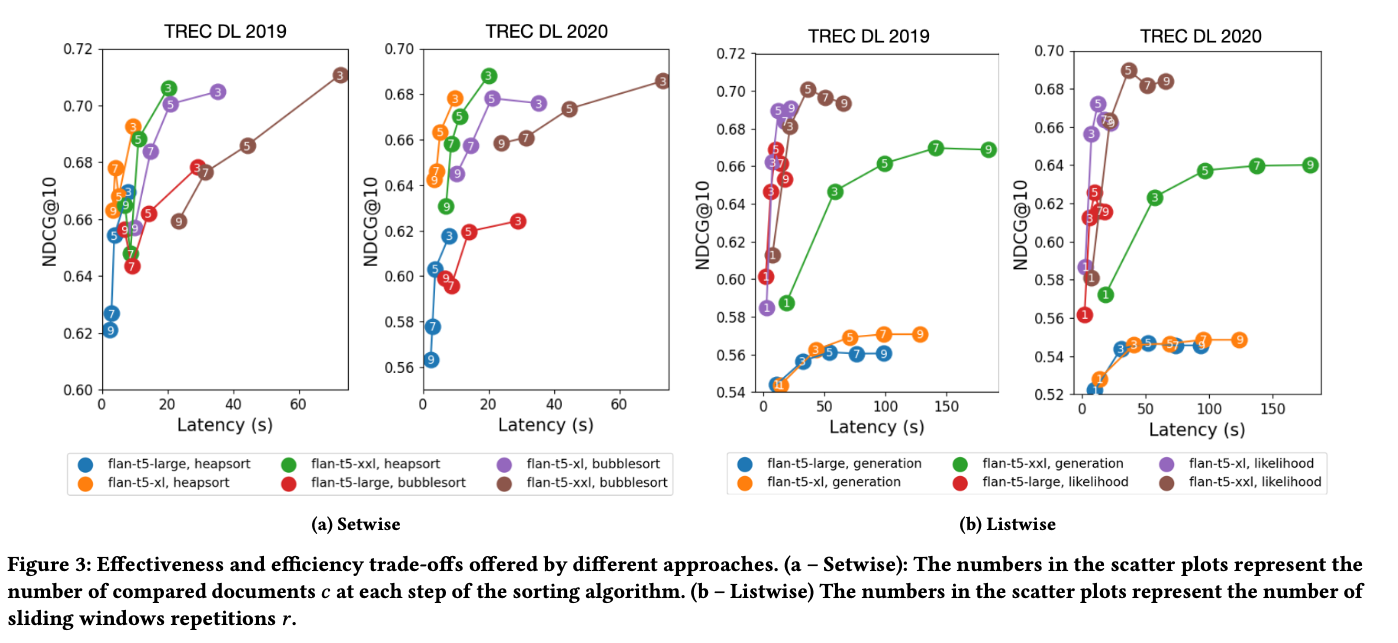
개인 견해
Zero-shot prompting 을 이용해 Re-ranking하는 관련연구에서 좀 단순한 아이디어였지만, LLM을 사용해 성능을 높힐 수있다는 점을 알 수 있었음. 연산량이 어마무시한 실험들을 해야하는데 이런 결과(리포팅 측면)에서 읽어두어도 괜찮았던 논문. 다만 setwise가 pairwise대비 속도 측면(이론적으로도 강하진 않음) 말고 성능면에서 credit을 얻기엔 부족한 부분이 있음.
LEAVE A COMMENT